Da hat er nach dem Deutschen Marketing Tag in Düsseldorf den Kanal wohl voll von Big Data, Analytics, Künstlicher Intelligenz oder Marketing Automation, der Thomas Knüwer. Den Eindruck gewinnt man, wenn man seinen Beitrag mit dem Titel über Warum Big Data und KI das Marketing in die falsche Richtung lotsen liest. In vielem hat er nach meiner Beobachtung als Marketer recht, doch manchmal schüttet er auch das Kind mit dem Bad aus.
Nein beziehungsweise ja, wir werden nicht jede Herausforderung im Marketing mit Technologie lösen:
Die Entscheider glauben, dass sie nur teure Technologie kaufen müssten – und alles wird wieder gut. Vor allem nimmt ihnen IT die Last, sich selbst und ihr Tun in den vergangenen 20 Jahren hinterfragen zu müssen
über Warum Big Data und KI das Marketing in die falsche Richtung lotsen – Indiskretion Ehrensache
Und Marketing ist sicher nicht gleich Marketing. Mir fällt natürlich sofort der Unterschied zwischen B2B, dem Verkauf von Produkten zwischen Unternehmen und für Unternehmen, und B2C, dem Verkauf von Produkten für normale Konsumenten, ein. Daneben gibt es sicher noch viele andere Unterschiede abhängig von Markt, Branche, Struktur der vermeintlichen. Kunden und viel anderen Nuancen.
Im Marketing dominiert der Glaube, ein Verbraucher oder Kunde definiere sich aus seinen Klicks und Käufen. …
Wer so denkt, für den ist es verlockend, in MarTech zu investieren, in Datenbanken und CRM-Systeme, in Big-Data-Anwendungen und KI-Programme. Oben kommen Zahlen rein, unten Zahlen wieder raus. Alles quantifzierbar, alles cover your ass.
über Warum Big Data und KI das Marketing in die falsche Richtung lotsen – Indiskretion Ehrensache
 Ja, nur zu oft wird über einen Kamm geschert und viel zu oft wird eine Lösung oder ein Trend vorbehaltlos, ja gedankenlos quer über alle Märkte postuliert. Das gilt sicher gerade für Marketingtechnologien, die überall hip zu sein scheinen, glaubt man den Vermarktern von Marketingtechnologien (zu denen ich gerade ja selbst in meinem derzeitigen Job für Acoustic gehöre). Aber Google Analytics ist nicht in jedem Falle der goldene Gral, Programmtic Advertising nicht das ultimative Fitness Programm für jedes Unternehmen.
Ja, nur zu oft wird über einen Kamm geschert und viel zu oft wird eine Lösung oder ein Trend vorbehaltlos, ja gedankenlos quer über alle Märkte postuliert. Das gilt sicher gerade für Marketingtechnologien, die überall hip zu sein scheinen, glaubt man den Vermarktern von Marketingtechnologien (zu denen ich gerade ja selbst in meinem derzeitigen Job für Acoustic gehöre). Aber Google Analytics ist nicht in jedem Falle der goldene Gral, Programmtic Advertising nicht das ultimative Fitness Programm für jedes Unternehmen.
Mancher von Technologie befeuerter Trend in Marketing und Werbung kann wirklich nerven, wie ich ja gerade selbst erfahren und berichtet habe. Ich will nicht den zwanzigsten Banner mit der gleichen Werbung auf jeder Webseite sehen, die ich besuche, vor allem wenn ich den Artikel bereits gekauft habe. Da läuft was grundlegend schief und das führt genau zu dem Phänomen, dass Thomas beschreibt: Immer mehr potentielle Kunden installieren Werbeblocker im Browser oder auf mobilen Endgeräten.
Wenn ich dann noch in meinem Segment, der Vermarktung von IT-Lösungen für Unternehmen, die leuchtenden Augen sehe, mit denen mancher Marketer die neue Analytics- oder Kampagnenlösung als Allheilmittel lobpreisen, bekomme ich Schnappatmung. Es scheint, dass viele Kolleginnen und Kollegen ihre Zeit nur noch hinter Dashboards verbringen und nicht wirklich Zeit, direkte qualitative Zeit, mit den Kunden verbringen. Ein Unding meiner Ansicht nach. Jenseits von oder neben agile, data-driven und Automatisierung: Jeder Marketer muss Zuhörer und Kommunikator sein.
Um es nochmals klar zu sagen: Die Aussage Schluss mit Data-driven Nonsense, die angesichts der Aussage von Adidas-Global Media Director Simon Peel,“Wir haben zu viel in digitale Werbung investiert“ leichfertig getroffen werden könnte, schießt über das Ziel hinaus. Wir Marketers müssen gerade jetzt mit modernen Technologien experimentieren, mit Künstlicher Intelligenz und Marketing Automation. Genau darüber habe ich mich ja auch auf der DMEXCO mit Gabriele Horcher unterhalten, die mir gerade das unten abgebildete Mailing zu gesendet hat. Aber wir müssen das Augenmaß behalten, die Balance zwischen Technologie und direktem Kontakt bewahren.

Denn neben den Technologien spielen gerade im B2B Marketing – und nicht nur dort – diese „anderen Aspekte“ eine mindestens genau so wichtige Rolle. Und da bin ich wieder bei Thomas. Es geht auch und vor allem darum, Beziehungen aufzubauen und zu pflegen, in Konversation zu treten und gerade auch so Erfahrungen und Emotionen zu schaffen, an die sich unsere Kunden und Interessenten erinnern. Dies wird nicht rein durch Technologien geschehen. Dafür kann beispielsweise das Zuhören in und der Dialog auf sozialen Medien sinnvoll sein.
Hat man ersten Kontakt entwickelt, können Kundenbeziehungen zum Beispiel in Communities verstärkt und gepflegt werden. Das Loblied der Communities singe ich nun schon seit Jahren. Selbst habe ich mich bewusst in meiner Zeit bei FileNet und auch als Marketijgverantwortlicher der Collaborationprodukte um die Anwendervereinigungen AWK oder DNUG gekümmert, auf Veranstaltungen und online in der entsprechenden Community. Denn jedem Verantwortlichen sollte klar sein, dass Communities auch moderiert werden müssen. Der Dialog dort sollte individuell und menschlich sein. Es geht um Qualitätszeit.
Thomas konstatiert zu recht, dass solche Aspekte derzeit keine oder eine zu geringe Rolle im deutschen Marketing spielen. Die Balance scheint derzeit verloren gegangen zu sein. Statt nur auf Technologie zu setzen und zu glauben, zu glauben, alles messen zu können, brauchen wir eine intelligente Mixtur, die je nach Geschäftsmodell oder Branche angepasst werden muss.
Gewinnen werden aber jene, die eine Mischung schaffen aus Big Data, Thick Data und wirklich kreativen Ideen. Die, die es schaffen, über Kommunikation eine echte Beziehung zu ihren Kunden herzustellen. Das ist beschwerlich und wird dauern, doch es wird sich auszahlen.
über Warum Big Data und KI das Marketing in die falsche Richtung lotsen – Indiskretion Ehrensache
Thomas gebraucht den wohl von Tricia Wang Begriff Thick Data, mit dem ich nicht so glücklich bin. Gemeint ist aber wohl etwas ähnliches: (Potentielle) Kunden sollten nicht nur Außerirdische sein, die sich Klicks und Klickwege sein. Die Beziehung zwischen Kunde und Marke beziehungsweise Unternehmen zählt, zählt auch in den Umsätzen und in der Kundenzufriedenheit. Und das gilt quer über Geschäftsmodelle und Branchen. Mancher Marketer täte gut daran, sich das zu Beginn des neuen Jahres in sein Dashboard zu schreiben …
(Stefan Pfeiffer)
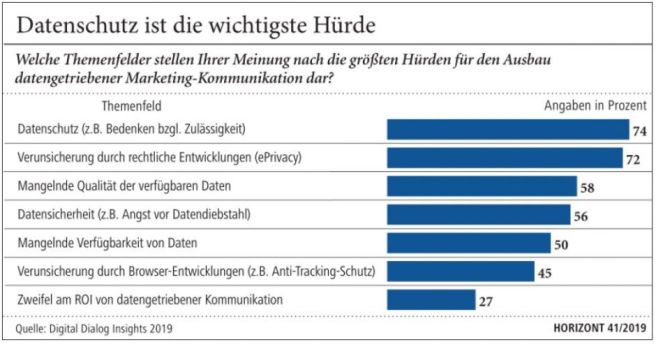

 (@365Sherpas)
(@365Sherpas) 








